Aufbau einer Echtzeit-IoT-Simulation mit Microsoft Fabric
- Michelle Schulz
- 27. Apr.
- 6 Min. Lesezeit
Echtzeit-Datenverarbeitung wird zunehmend zu einem zentralen Bestandteil moderner Datenplattformen. Anstatt Daten zunächst zu sammeln und später zu analysieren, müssen Unternehmen immer häufiger unmittelbar reagieren, sobald Ereignisse auftreten.

Milka Kutseva
Senior Data Engineer
Dieser Wandel wird durch die steigende Nachfrage nach schnelleren Erkenntnissen und reaktionsfähigeren Systemen getrieben. In vielen Szenarien können bereits kurze Verzögerungen den Wert von Daten reduzieren oder kritische Entscheidungsprozesse beeinträchtigen. Echtzeitverarbeitung ist insbesondere in Bereichen wie IoT-Monitoring, Systemüberwachung und Anomalieerkennung relevant, in denen kontinuierlich Daten erzeugt werden und ohne Verzögerung interpretiert werden müssen.
Dieser Blogbeitrag erläutert die Grundlagen von Echtzeit-Datenströmen und demonstriert diese anhand einer einfachen IoT-Simulation in Microsoft Fabric.
Von Batch zu Echtzeit-Denken
Viele traditionelle Systeme basieren auf Batch-Verarbeitung, bei der Daten in bestimmten Intervallen gesammelt und verarbeitet werden – beispielsweise stündlich oder einmal täglich.
Dieser Ansatz eignet sich gut für historische Analysen, führt jedoch zu Verzögerungen zwischen Datenerzeugung und Erkenntnisgewinn. In dynamischen Umgebungen kann genau diese Verzögerung zum Problem werden.
Echtzeitsysteme verfolgen einen anderen Ansatz:
Daten werden kontinuierlich erzeugt
Ereignisse werden sofort verarbeitet, sobald sie eintreffen
Erkenntnisse stehen nahezu in Echtzeit zur Verfügung
Dadurch können Unternehmen von einem reaktiven zu einem proaktiven Verhalten übergehen. Anstatt zu analysieren, was bereits passiert ist, können sie reagieren, während Ereignisse noch stattfinden.
Gleichzeitig erfordern Echtzeitsysteme ein Umdenken, da Daten nicht mehr statisch sind – sie verändern sich kontinuierlich.
Echtzeit Architektur in Microsoft Fabric

Architekturverständnis
Die oben dargestellte Architektur zeigt, wie Echtzeitdaten durch Microsoft Fabric fließen und wie die einzelnen Komponenten zusammenwirken, um eine vollständige Streaming-Lösung zu ermöglichen.
Der Prozess lässt sich in drei Hauptphasen unterteilen:
1) Ingest & Process
Daten werden aus verschiedenen Quellen wie APIs, Datenbanken oder Streaming-Systemen erfasst. Eventstream übernimmt die Aufgabe, diese Daten zu empfangen und als kontinuierlichen Datenstrom zu verarbeiten.
In dieser Phase stehen Zuverlässigkeit und Geschwindigkeit im Fokus, um sicherzustellen, dass Ereignisse ohne Verzögerung und ohne Datenverlust aufgenommen werden.
2) Analyze & Transform
Nach der Aufnahme können die Daten im Eventhouse gespeichert und analysiert werden, das für die schnelle Verarbeitung von Streaming-Daten optimiert ist.
Hier wird aus Rohdaten ein nutzbarer Datenbestand: Daten können gefiltert, strukturiert oder angereichert werden – je nach Anforderung der Lösung.
3) Visualize & Act
Die verarbeiteten Daten werden anschließend genutzt für:
Dashboards mit Live-Daten
Reports für tiefergehende Analysen
Automatisierte Aktionen, die durch bestimmte Bedingungen ausgelöst werden
Dadurch wird nicht nur Beobachtung, sondern auch Automatisierung ermöglicht – ein zentraler Vorteil von Echtzeitsystemen.
Die Grundlage dieser Architektur bildet OneLake, das eine einheitliche Speicherschicht bereitstellt und das nahtlose Zusammenspiel aller Komponenten ermöglicht.
Funktionsweise von Echtzeit-Datenpipelines
Eine Echtzeit-Datenpipeline folgt einem einfachen, aber leistungsstarken Prinzip: Daten fließen kontinuierlich durch das System, anstatt in großen Batches verarbeitet zu werden.
Die zentralen Schritte sind:
Daten werden erzeugt (z. B. durch Geräte oder Anwendungen)
Sie werden über eine Ingestion-Schicht in die Plattform eingespeist
Sie werden beim Eintreffen verarbeitet oder transformiert
Sie werden für Analysen oder weitere Nutzung gespeichert
Sie werden visualisiert oder lösen Aktionen aus
Jedes Ereignis ist Teil eines fortlaufenden Datenstroms, und das System aktualisiert seinen Zustand kontinuierlich auf Basis neuer Informationen.
Dieser Ansatz ermöglicht nahezu Echtzeit-Einblicke, erfordert jedoch eine sorgfältige Architektur, um Stabilität und Performance sicherzustellen.
Möglichkeiten zur Datenaufnahme in Fabric
Microsoft Fabric bietet verschiedene Möglichkeiten zur Aufnahme von Streaming-Daten, abhängig von der Komplexität des Szenarios:
API / Custom Endpoint
Eine einfache und flexible Option, häufig für Tests und Simulationen genutzt. Daten können direkt aus Skripten oder Anwendungen gesendet werden.
Event Hubs oder Kafka
Fortgeschrittene Optionen für produktive Umgebungen, in denen große Datenmengen zuverlässig und skalierbar verarbeitet werden müssen.
Power Automate
Eine Low-Code-Alternative, mit der sich ereignisgesteuerte Prozesse ohne Programmierung erstellen lassen – besonders geeignet für Fachanwender.
Use Case: IoT Monitoring
Zur Veranschaulichung wurde ein einfaches IoT-Szenario umgesetzt.
Dabei werden Sensoren in verschiedenen Räumen simuliert, die folgende Werte senden:
Temperatur
Luftfeuchtigkeit
CO₂-Werte
Zeitstempel
Ziel ist es, diese Werte kontinuierlich zu überwachen, ungewöhnliche Situationen zu erkennen und bei Bedarf zu reagieren.
Solche Szenarien sind typisch für reale Anwendungen wie Smart Buildings, industrielle Überwachung oder Umweltmonitoring.
Datensimulation mit Python
Anstatt reale Geräte anzubinden, wurden die Daten über ein Python-Skript generiert.
Das Skript erzeugt zufällige Werte und sendet diese in regelmäßigen Abständen, wodurch ein Live-Datenstrom simuliert wird.
Dieser Ansatz ist besonders für Demonstrationen geeignet, da er volle Kontrolle über die Daten ermöglicht und das Testen unterschiedlicher Szenarien – inklusive Anomalien – erleichtert.

Eventstream: Echtzeit-Datenaufnahme
Eventstream ist verantwortlich für den Empfang der eingehenden Daten und deren Weiterleitung an die entsprechenden Zielsysteme.
Es fungiert als zentrale Komponente, die Datenquellen mit Speicher- und Analyseebenen verbindet.
Zusätzlich ermöglicht Eventstream grundlegende Verarbeitungsschritte wie:
Filtern von Ereignissen
Anpassen von Feldern
Vorbereitung der Daten vor der Speicherung
In diesem Beispiel waren die Daten bereits strukturiert, sodass nur minimale Transformationen erforderlich waren. In realen Szenarien ist dieser Schritt jedoch oft entscheidend, um Datenkonsistenz sicherzustellen.

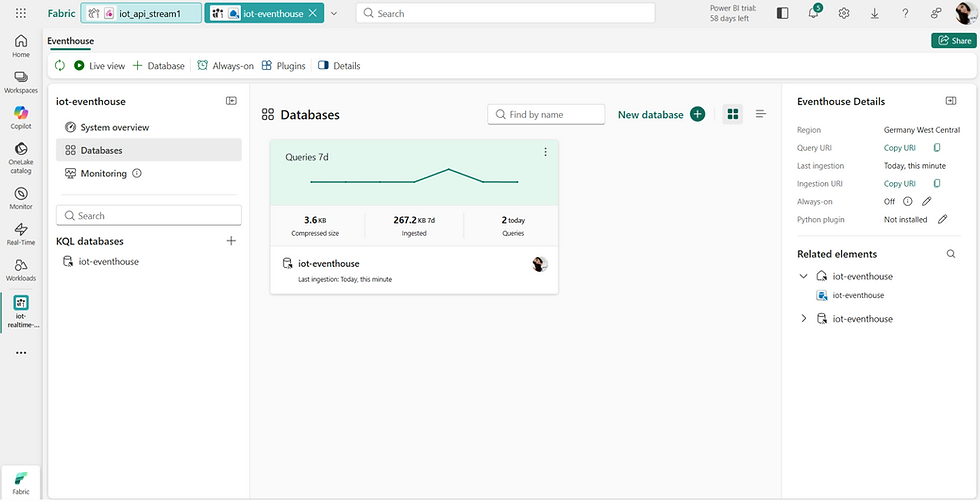
Eventhouse und Speicheroptionen
Die eingehenden Daten werden im Eventhouse gespeichert, das für Echtzeitanalysen und schnelle Abfragen von Streaming-Daten optimiert ist. Es ermöglicht einen effizienten Zugriff auf kontinuierlich ingestierte Ereignisse und unterstützt interaktive Analysen mit minimaler Latenz.
Im Kern von Eventhouse steht die KQL-Datenbank. KQL steht für Kusto Query Language, eine Abfragesprache, die ursprünglich für die Azure Data Explorer (Kusto) Engine entwickelt wurde, welche speziell für großskalige Log- und Telemetrieanalysen konzipiert ist.
Im Gegensatz zu klassischen relationalen Datenbanken ist die KQL-Datenbank für High-Ingestion- und Append-only-Workloads ausgelegt. Neue Ereignisse werden kontinuierlich in das System geschrieben, während bestehende Datensätze nur selten aktualisiert werden. Dieses Design macht sie besonders effizient für Szenarien wie IoT-Daten, Monitoring und Event-Tracking.
Die Daten werden in Tabellen mit einem vordefinierten Schema gespeichert, wobei jedes eingehende Ereignis als neue Zeile erfasst wird. Da die Ingestion schema-basiert erfolgt, müssen Spaltennamen und Datentypen mit der Definition der Zieltabelle übereinstimmen, um eine korrekte Verarbeitung sicherzustellen.
Die KQL-Engine ist für spaltenbasierte Speicherung und Abfrageausführung optimiert, wodurch große Datenmengen sehr schnell gescannt und aggregiert werden können. Anstatt sich auf transaktionale Operationen zu konzentrieren, ist sie für analytische Workloads ausgelegt, bei denen es darum geht, Daten zu explorieren und zusammenzufassen, anstatt sie zu verändern.
Ein weiteres zentrales Merkmal ist die starke Unterstützung für zeitbasierte Daten. Da die meisten Streaming-Daten Zeitstempel enthalten, ist die Engine darauf optimiert, Daten über Zeitintervalle zu filtern, zu gruppieren und zu analysieren. Dadurch eignet sie sich besonders gut zur Erkennung von Trends, zur Identifikation von Anomalien und zum Abrufen des aktuellen Systemzustands.
Zusätzlich bietet KQL integrierte Funktionen für Aggregationen, Windowing und Echtzeit-Filterung, die schnelle und ausdrucksstarke Analysen ohne komplexe Abfragelogik ermöglichen. Dadurch ist sie besonders gut geeignet für Monitoring-Dashboards und Near-Real-Time-Analytics-Szenarien.
Weitere Speicheroptionen in Fabric
Eventhouse ist nur ein Bestandteil der Plattform. Je nach Anwendungsfall können auch andere Speicheroptionen genutzt werden:
Eventhouse (KQL-Datenbank)
Am besten geeignet für Echtzeitszenarien und schnelle Abfragen von Streaming-Daten. Optimiert für Zeitreihenanalysen, Monitoring und Anomalieerkennung. Liefert Near-Real-Time-Insights und unterstützt ereignisgetriebene Architekturen.
Lakehouse
Wird für die Speicherung großer Mengen historischer Daten verwendet, typischerweise in Formaten wie Delta oder Parquet. Besonders geeignet für Data Engineering, Batch-Verarbeitung und Advanced Analytics.
Warehouse
Konzipiert für strukturierte Daten und klassische Reporting-Anwendungsfälle. Unterstützt SQL-basierte Abfragen und wird häufig in Business-Intelligence-Szenarien eingesetzt.
Echtzeit-Alerts mit Activator
Ein wesentlicher Vorteil von Echtzeitsystemen ist die Möglichkeit, automatisch auf Ereignisse zu reagieren.
Mit Activator können Regeln definiert werden, z. B.:Wenn die Temperatur einen bestimmten Schwellenwert überschreitet, wird ein Alert ausgelöst.
Benachrichtigungen können z. B. per E-Mail versendet werden, sodass Nutzer nicht permanent Dashboards überwachen müssen.
Damit wird aus passivem Monitoring ein aktives, automatisiertes System.

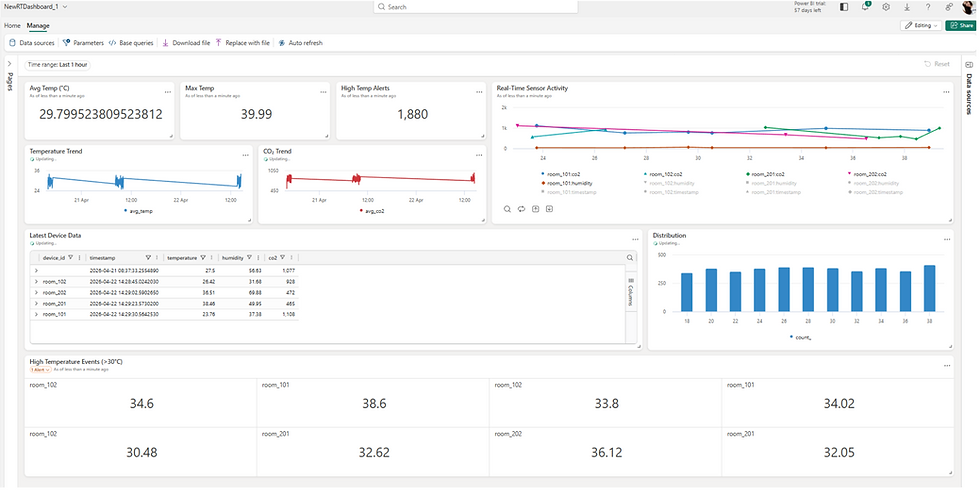
Visualisierung
Streaming-Daten können je nach Ziel unterschiedlich visualisiert werden:
Echtzeit-Dashboards für aktuelle Werte
Reporting-Tools wie Power BI für tiefere Analysen
Visualisierung ist entscheidend, da sie Rohdaten in verständliche Informationen übersetzt.
Kosten
Die Nutzung von Eventstreams erfordert eine kostenpflichtige Microsoft-Fabric-Kapazität.
Das geeignete Kapazitätsniveau hängt von mehreren Faktoren ab, darunter das Volumen der eingehenden Daten, wie häufig Ereignisse verarbeitet werden und wie lange die Streaming-Pipelines ausgeführt werden.
Für kleinere Workloads können niedrigere Kapazitätsstufen ausreichend sein, während komplexere oder datenintensive Szenarien höhere Kapazitäten erfordern.
Weitere Informationen zu den Preisen finden Sie hier.
Es ist außerdem wichtig zu überwachen, wie Ressourcen genutzt werden – insbesondere in Echtzeitszenarien, in denen die Verarbeitung kontinuierlich erfolgt. Hinweise zur Überwachung der Kapazitätsauslastung finden Sie hier.
Zur Kostenoptimierung können Eventstreams pausiert oder deaktiviert werden, wenn sie nicht benötigt werden. Dadurch wird unnötige Last reduziert und die Effizienz der Umgebung erhöht.
Fazit
Echtzeit-Datenverarbeitung ermöglicht es Unternehmen, über klassische Batch-Systeme hinauszugehen und unmittelbar auf Ereignisse zu reagieren, sobald diese auftreten.
Mit Microsoft Fabric lässt sich eine vollständige Echtzeit-Datenpipeline mit vergleichsweise geringem Setup aufbauen, indem Ingestion, Verarbeitung, Speicherung und Visualisierung in einer Plattform kombiniert werden.
Selbst anhand einer einfachen Simulation wird deutlich, wie Daten kontinuierlich fließen, nahezu in Echtzeit analysiert werden können und Systeme automatisch reagieren, sobald definierte Bedingungen erfüllt sind.



Kommentare